Looker
PRODIn this section, we provide guides and references to use the Looker connector.
Configure and schedule Looker metadata and profiler workflows from the OpenMetadata UI:
Requirements
There are two types of metadata we ingest from Looker:
- Dashboards & Charts
- LookML Models
For the project metadata being ingested:
- We get the actual LookML Project an Explore or View is developed in.
- For Dashboards, we use the folder name from the UI, since there is no other hierarchy involved there.
In terms of permissions, we need a user with access to the Dashboards and LookML Explores that we want to ingest. You can create your API credentials following these docs.
However, LookML Views are not present in the Looker SDK. Instead, we need to extract that information directly from the GitHub repository holding the source .lkml files. In order to get this metadata, we will require a GitHub token with read only access to the repository. You can follow these steps from the GitHub documentation.
The GitHub credentials are completely optional. Just note that without them, we won't be able to ingest metadata out of LookML Views, including their lineage to the source databases.
Moreover, Looker lineage only supports LookML views configured with sql_table_name and derived_table in plain SQL. We do not yet support liquid variables.
Metadata Ingestion
1. Visit the Services Page
Click Settings in the side navigation bar and then Services.
The first step is to ingest the metadata from your sources. To do that, you first need to create a Service connection first.
This Service will be the bridge between OpenMetadata and your source system.
Once a Service is created, it can be used to configure your ingestion workflows.
Select your Service Type and Add a New Service
Add a new Service from the Services page
Select your Service from the list
4. Name and Describe your Service
Provide a name and description for your Service.
Service Name
OpenMetadata uniquely identifies Services by their Service Name. Provide a name that distinguishes your deployment from other Services, including the other Looker Services that you might be ingesting metadata from.
Note that when the name is set, it cannot be changed.
Provide a Name and description for your Service
5. Configure the Service Connection
In this step, we will configure the connection settings required for Looker.
Please follow the instructions below to properly configure the Service to read from your sources. You will also find helper documentation on the right-hand side panel in the UI.
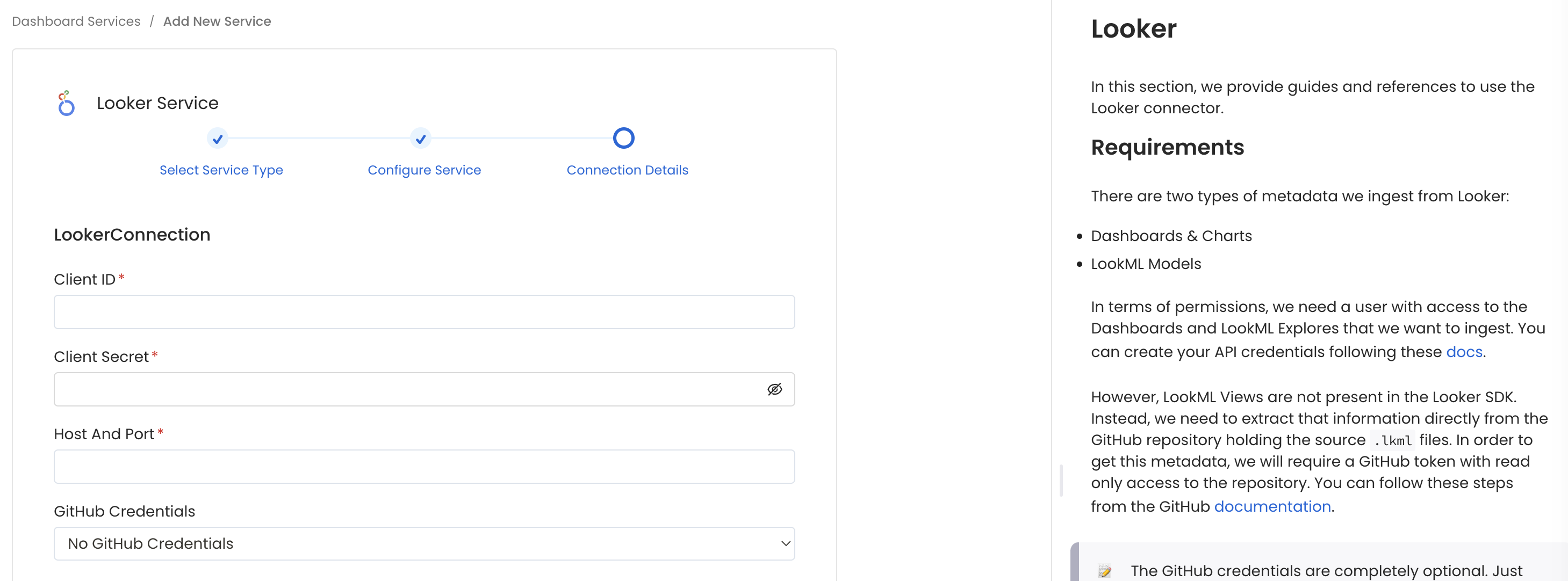
Configure the Service connection by filling the form
Connection Details
When using a Hybrid Ingestion Runner, any sensitive credential fields—such as passwords, API keys, or private keys—must reference secrets using the following format:
This applies only to fields marked as secrets in the connection form (these typically mask input and show a visibility toggle icon).
For a complete guide on managing secrets in hybrid setups, see the Hybrid Ingestion Runner Secret Management Guide.
- Host and Port: URL to the Looker instance, e.g.,
https://my-company.region.looker.com. - Client ID: User's Client ID to authenticate to the SDK. This user should have privileges to read all the metadata in Looker.
- Client Secret: User's Client Secret for the same ID provided.
Then, if we choose to inform the GitHub credentials to ingest LookML Views:
- Repository Owner: The owner (user or organization) of a GitHub repository. For example, in https://github.com/open-metadata/OpenMetadata, the owner is
open-metadata. - Repository Name: The name of a GitHub repository. For example, in https://github.com/open-metadata/OpenMetadata, the name is
OpenMetadata. - API Token: Token to use the API. This is required for private repositories and to ensure we don't hit API limits.
Follow these steps in order to create a fine-grained personal access token.
When configuring, give repository access to Only select repositories and choose the one containing your LookML files. Then, we only need Repository Permissions as Read-only for Contents.
6. Test the Connection
Once the credentials have been added, click on Test Connection and Save the changes.
Test the connection and save the Service
7. Configure Metadata Ingestion
In this step we will configure the metadata ingestion pipeline, Please follow the instructions below
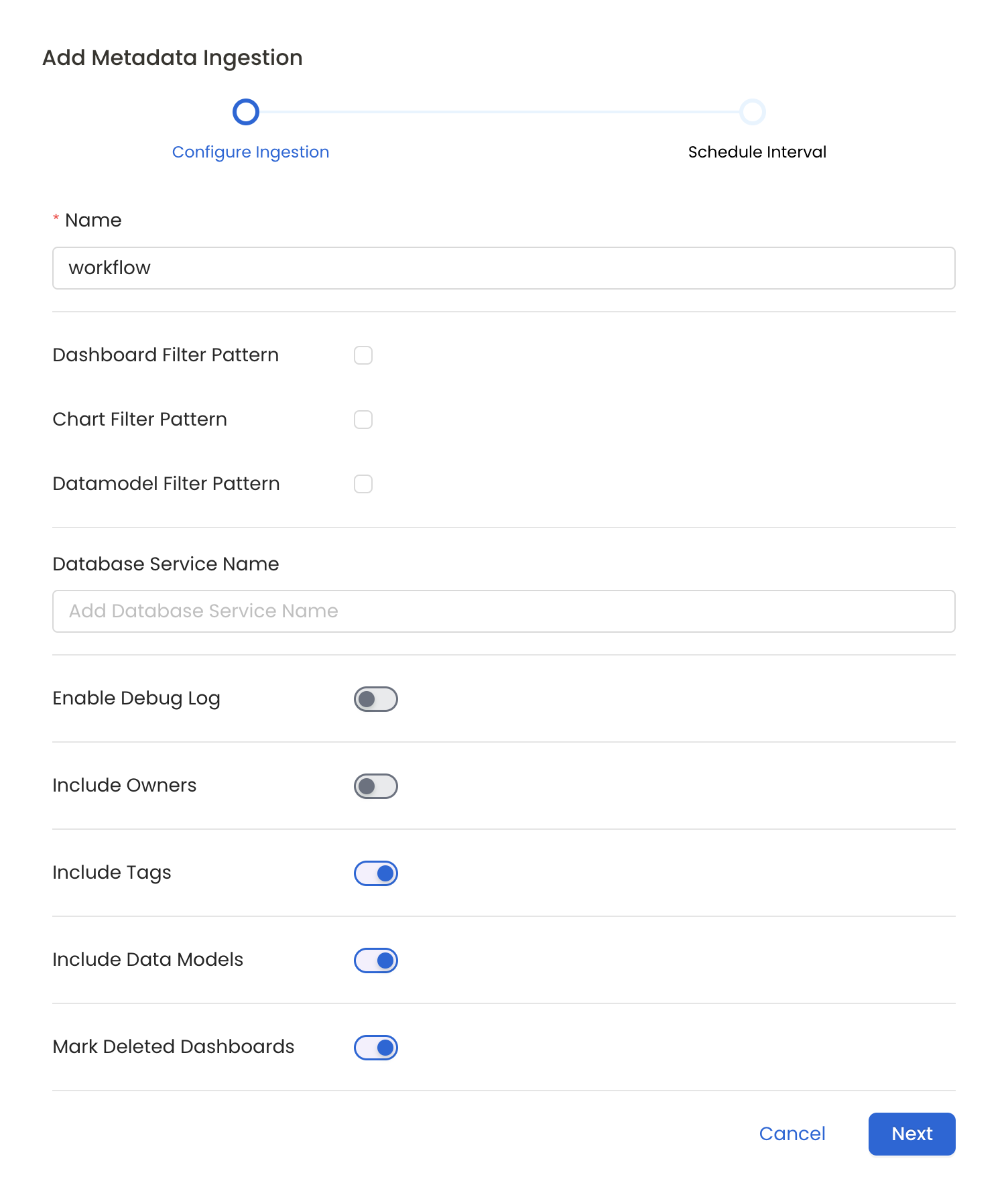
Configure Metadata Ingestion Page
Metadata Ingestion Options
- Name: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
- Dashboard Filter Pattern (Optional): Use it to control whether to include dashboard as part of metadata ingestion.
- Include: Explicitly include dashboards by adding a list of comma-separated regular expressions to the 'Include' field. OpenMetadata will include all dashboards with names matching one or more of the supplied regular expressions. All other dashboards will be excluded.
- Exclude: Explicitly exclude dashboards by adding a list of comma-separated regular expressions to the 'Exclude' field. OpenMetadata will exclude all dashboards with names matching one or more of the supplied regular expressions. All other dashboards will be included.
- projectFilterPattern: Filter the dashboards, charts and data sources by projects. Note that all of them support regex as include or exclude. E.g., "My project, My proj.*, .*Project".
We filter the projects by concatenating the entire project hierarchy using dot notation
(e.g., Project1.NestedProjectA.OtherProject).
Make sure the regex filter pattern accounts for this fully-qualified format.
- Chart Pattern (Optional): Use it to control whether to include charts as part of metadata ingestion.
- Include: Explicitly include charts by adding a list of comma-separated regular expressions to the 'Include' field. OpenMetadata will include all charts with names matching one or more of the supplied regular expressions. All other charts will be excluded.
- Exclude: Explicitly exclude charts by adding a list of comma-separated regular expressions to the 'Exclude' field. OpenMetadata will exclude all charts with names matching one or more of the supplied regular expressions. All other charts will be included.
- Data Model Pattern (Optional): Use it to control whether to include data modes as part of metadata ingestion.
- Include: Explicitly include data models by adding a list of comma-separated regular expressions to the 'Include' field. OpenMetadata will include all data models with names matching one or more of the supplied regular expressions. All other data models will be excluded.
- Exclude: Explicitly exclude data models by adding a list of comma-separated regular expressions to the 'Exclude' field. OpenMetadata will exclude all data models with names matching one or more of the supplied regular expressions. All other data models will be included.
- Db Service Prefixes (Optional): Enter the names of Database Services which are already ingested in OpenMetadata to create lineage between dashboards and database tables.
- Enable Debug Log (toggle): Set the 'Enable Debug Log' toggle to set the default log level to debug.
- Include Owners (toggle): Set the 'Include Owners' toggle to control whether to include owners to the ingested entity if the owner email matches with a user stored in the OM server as part of metadata ingestion. If the ingested entity already exists and has an owner, the owner will not be overwritten.
- Include Tags (toggle): Set the 'Include Tags' toggle to control whether to include tags in metadata ingestion.
- Include Data Models (toggle): Set the 'Include Data Models' toggle to control whether to include tags as part of metadata ingestion.
- Mark Deleted Dashboards (toggle): Set the 'Mark Deleted Dashboards' toggle to flag dashboards as soft-deleted if they are not present anymore in the source system.
- Include Draft Dashboard (toggle): Set the 'Include Draft Dashboard' toggle to include draft dashboards. By default it will include draft dashboards.
8. Schedule the Ingestion and Deploy
Scheduling can be set up at an hourly, daily, weekly, or manual cadence. The timezone is in UTC. Select a Start Date to schedule for ingestion. It is optional to add an End Date.
Review your configuration settings. If they match what you intended, click Deploy to create the service and schedule metadata ingestion.
If something doesn't look right, click the Back button to return to the appropriate step and change the settings as needed.
After configuring the workflow, you can click on Deploy to create the pipeline.
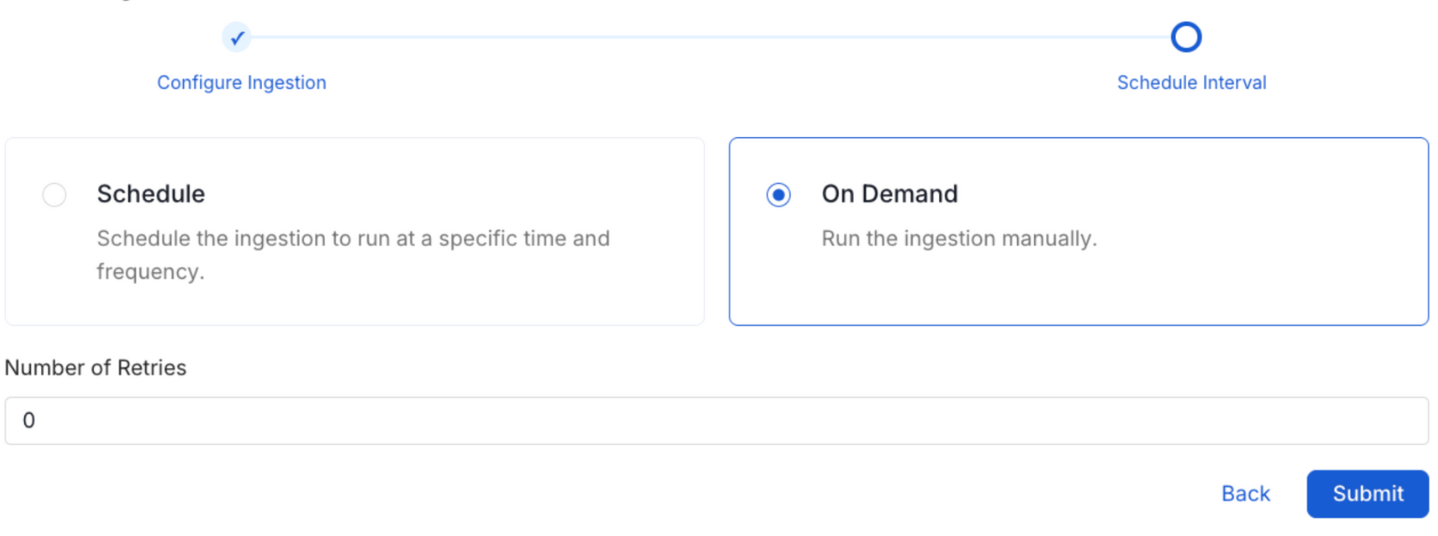
Schedule the Ingestion Pipeline and Deploy
9. View the Ingestion Pipeline
Once the workflow has been successfully deployed, you can view the Ingestion Pipeline running from the Service Page.
View the Ingestion Pipeline from the Service Page
If AutoPilot is enabled, workflows like usage tracking, data lineage, and similar tasks will be handled automatically. Users don’t need to set up or manage them - AutoPilot takes care of everything in the system.
Lineage
To establish lineage from your database tables to dashboards, you must add the corresponding database service name.
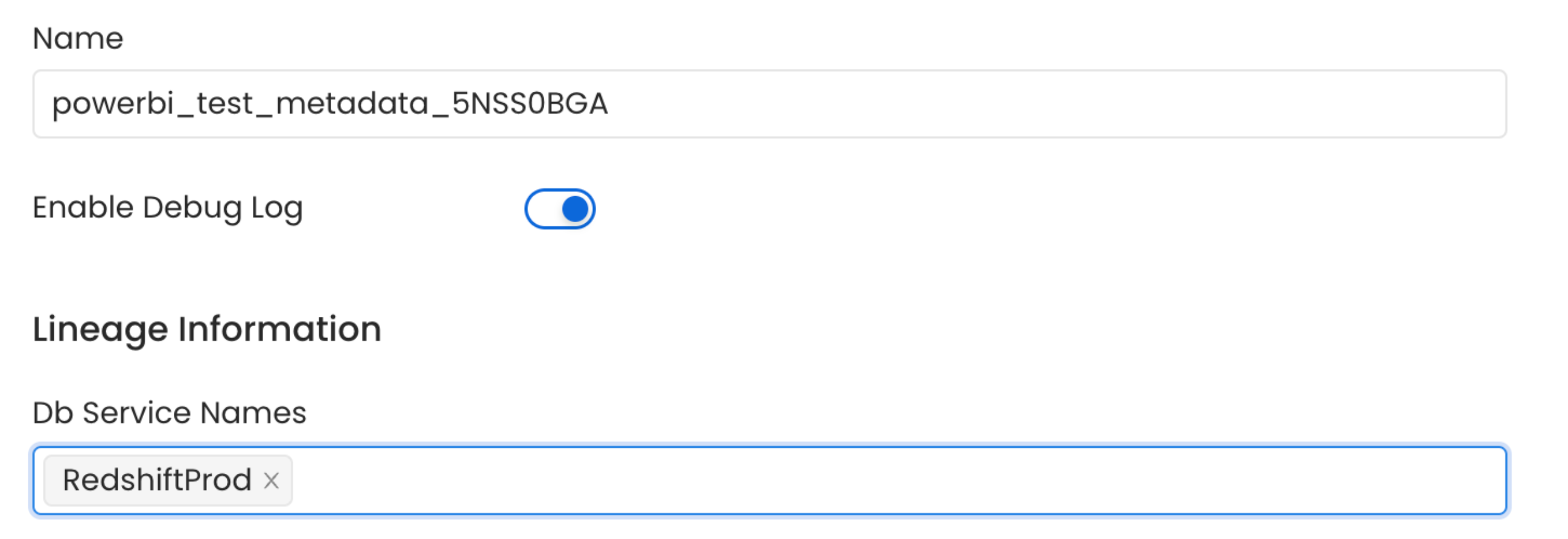
Lineage in Dashboard