Usage Workflow
Learn how to configure the Usage workflow from the UI to ingest Query history data from your data sources.
This workflow is available ONLY for the following connectors:
If your database service is not yet supported, you can use this same workflow by providing a Query Log file!
Learn how to do so 👇
UI Configuration
Once the metadata ingestion runs correctly and we are able to explore the service Entities, we can add Query Usage information.
This will populate the Queries tab from the Table Entity Page.
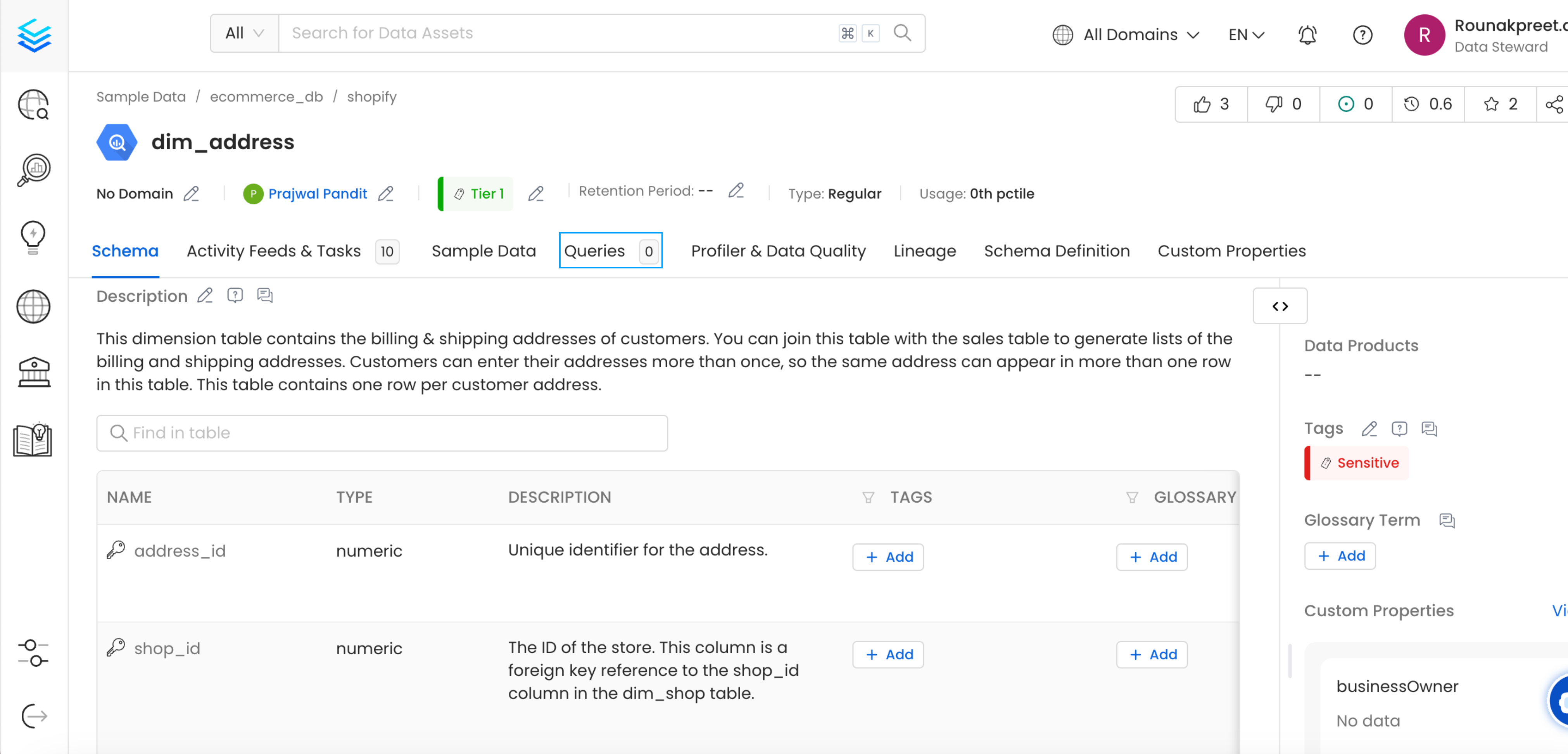
Table Entity Page
We can create a workflow that will obtain the query log and table creation information from the underlying database and feed it to OpenMetadata. The Usage Ingestion will be in charge of obtaining this data.
1. Add a Usage Ingestion
From the Service Page, go to the Ingestions tab to add a new ingestion and click on Add Usage Ingestion.
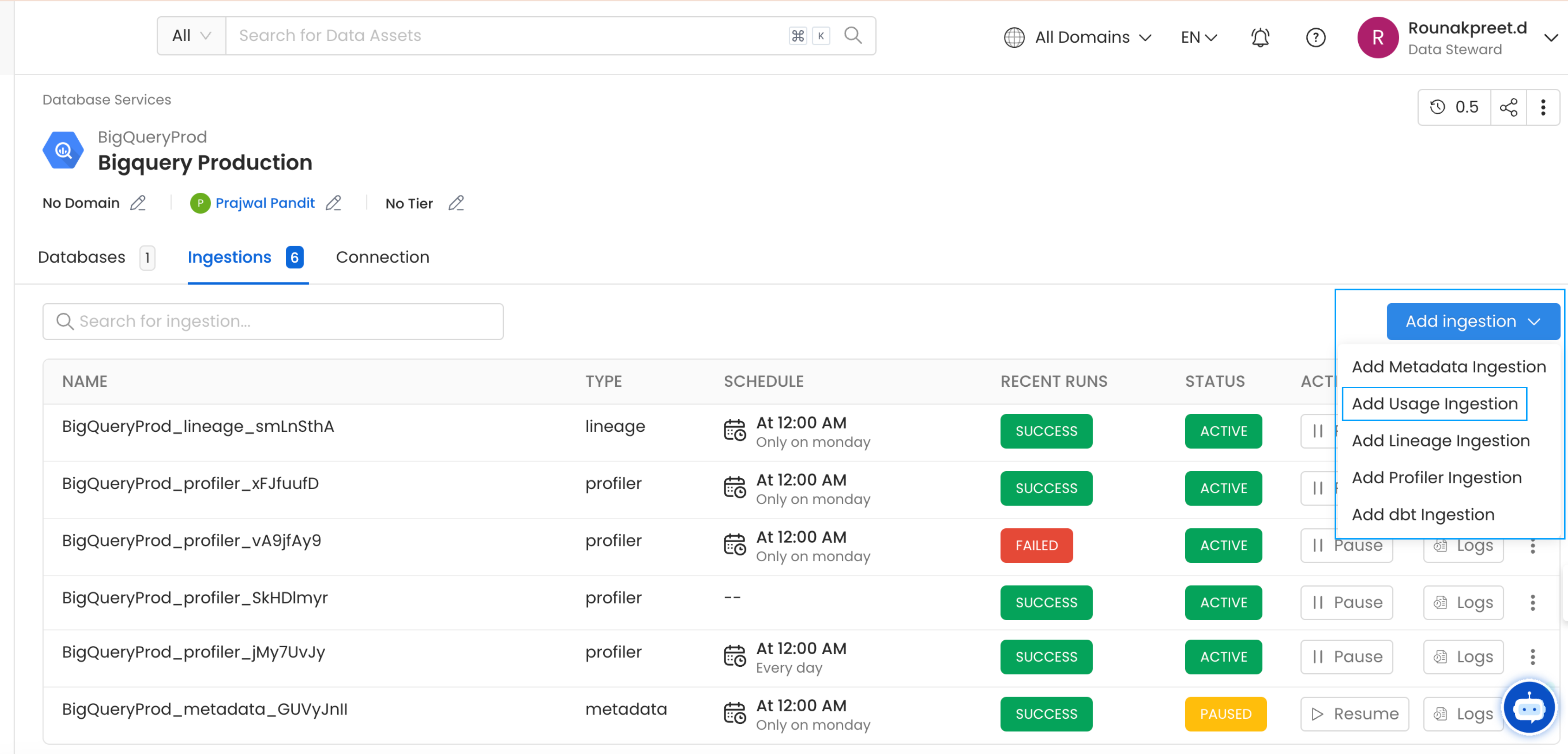
Add Ingestion
2. Configure the Usage Ingestion
Here you can enter the Usage Ingestion details:
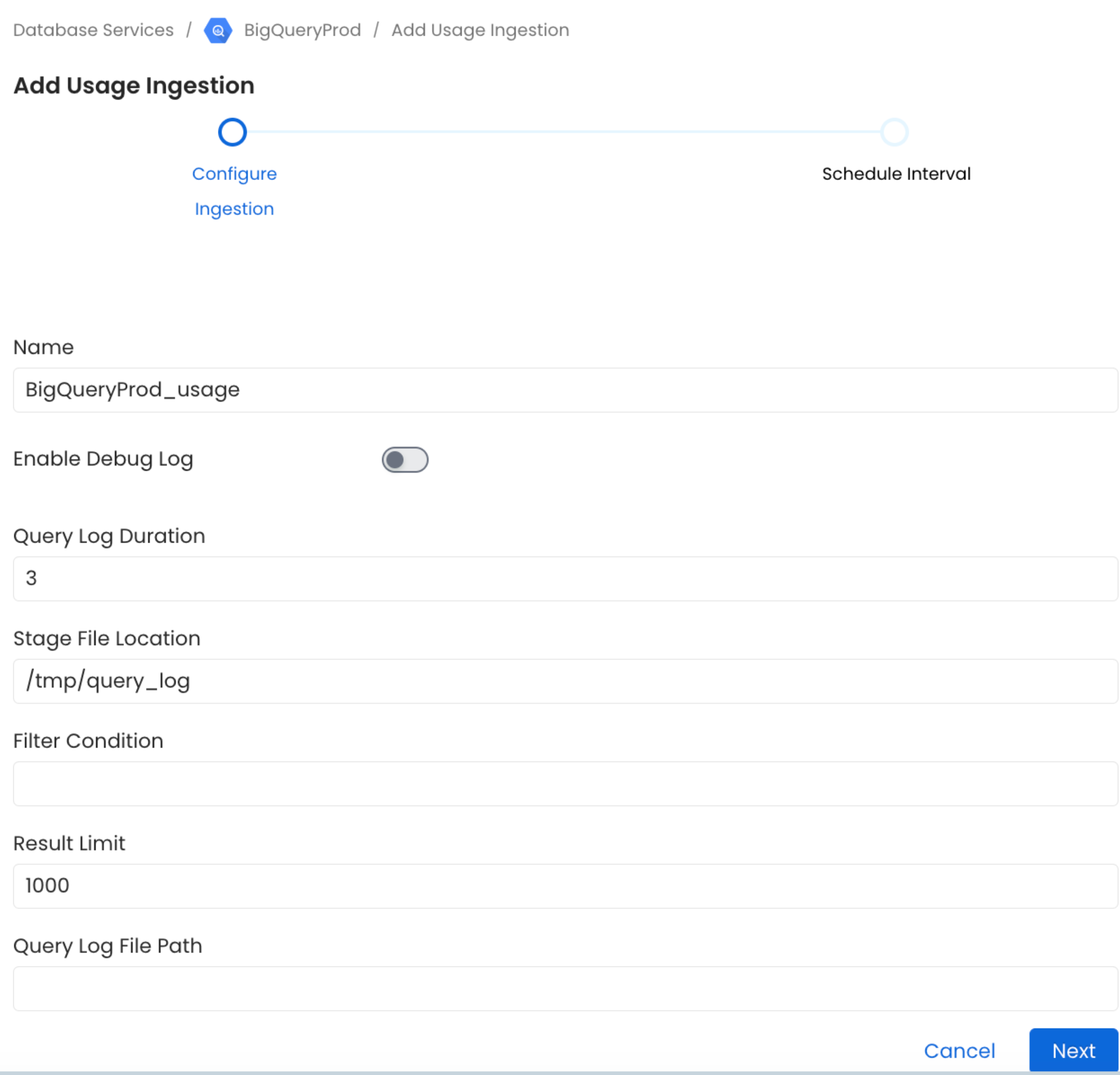
Configure the Usage Ingestion
Usage Options
Query Log Duration
Specify the duration in days for which the usage should capture usage data from the query logs. For example, if you specify 2 as the value for the duration, the data usage will capture usage information for 48 hours prior to when the ingestion workflow is run.
Stage File Location
Mention the absolute file path of the temporary file name to store the query logs before processing.
Result Limit
Set the limit for the query log results to be run at a time.
3. Schedule and Deploy
After clicking Next, you will be redirected to the Scheduling form. This will be the same as the Metadata Ingestion. Select your desired schedule and click on Deploy to find the usage pipeline being added to the Service Ingestions.
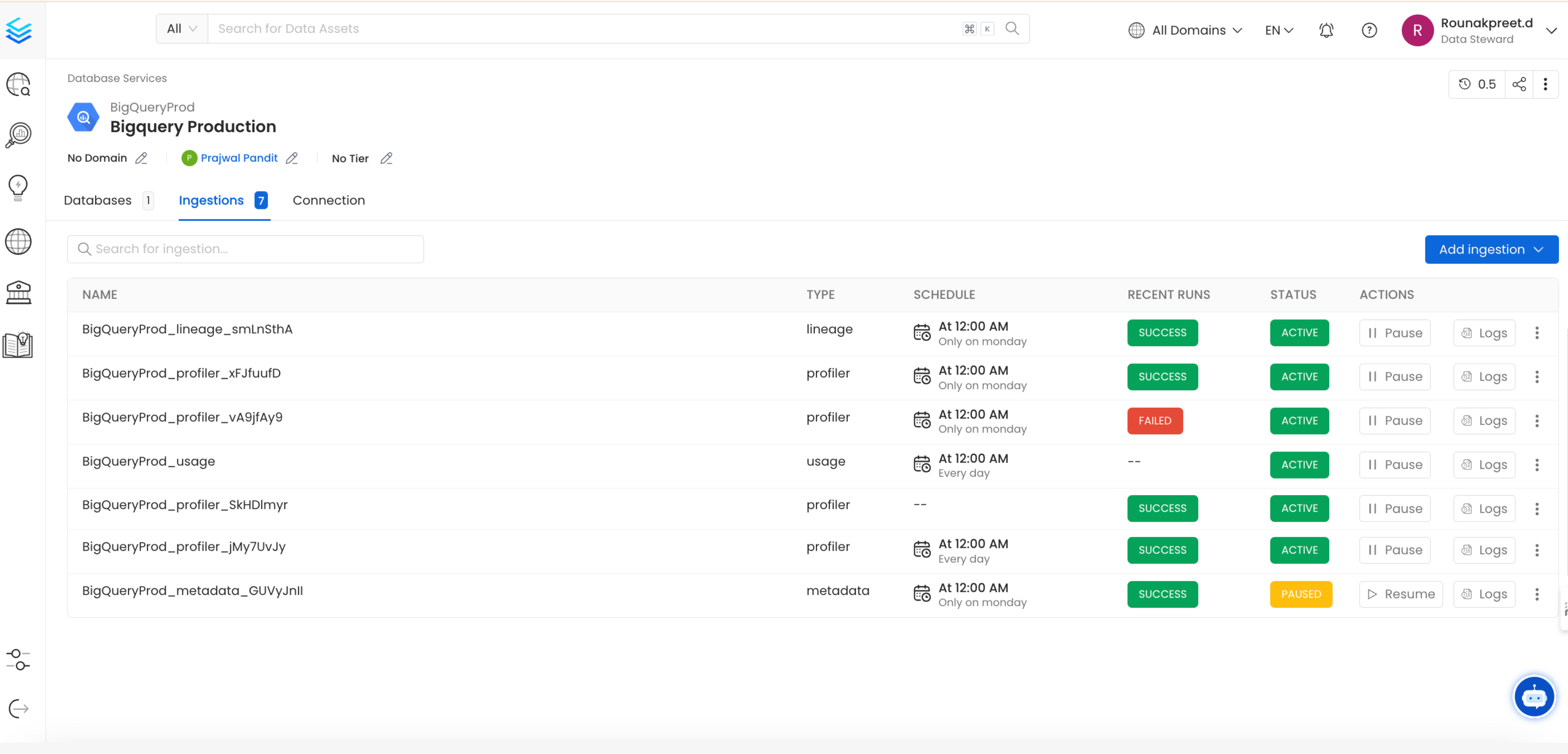
View Service Ingestion pipelines
YAML Configuration
In the connectors section we showcase how to run the metadata ingestion from a JSON/YAML file using the Airflow SDK or the CLI via metadata ingest. Running a usage workflow is also possible using a JSON/YAML configuration file.
This is a good option if you wish to execute your workflow via the Airflow SDK or using the CLI; if you use the CLI a usage workflow can be triggered with the command metadata usage -c FILENAME.yaml. The serviceConnection config will be specific to your connector (you can find more information in the connectors section), though the sourceConfig for the usage will be similar across all connectors.
Query Usage
The Query Usage workflow will be using the query-parser processor.
After running a Metadata Ingestion workflow, we can run Query Usage workflow. While the serviceName will be the same to that was used in Metadata Ingestion, so the ingestion bot can get the serviceConnection details from the server.
1. Define the YAML Config
This is a sample config for BigQuery Usage:
Source Configuration - Source Config
You can find all the definitions and types for the sourceConfig here.
queryLogDuration: Configuration to tune how far we want to look back in query logs to process usage data.
stageFileLocation: Temporary file name to store the query logs before processing. Absolute file path required.
resultLimit: Configuration to set the limit for query logs
queryLogFilePath: Configuration to set the file path for query logs
2. Run with the CLI
After saving the YAML config, we will run the command the same way we did for the metadata ingestion: